
By Gaurav Shekhadiya, Flexion
Introduction
In the land of big data, EMR (Elastic MapReduce) Serverless is a recent addition to the EMR family and has the ability to process and analyze large datasets with increased efficiency, cost-effectiveness, simplicity – and more.
In this article, we:
- Answer some basic questions about this product.
- Explore the benefits of EMR Serverless over EMR Cluster, including some key considerations.
- Include step-by-step instructions, as a blueprint to migrate from EMR Cluster to EMR Serverless.
- Look at the three essential components of the EMR Serverless job setup.
Use this information to help you decide if this software will work for you.
When did AWS EMR come on the scene?
Amazon EMR Serverless (formerly known as Elastic MapReduce) was released on June 1, 2022, as an alternative to EMR Cluster.
What is AWS EMR?
AWS EMR is a Big Data framework for processing large amounts of data by offering a lightweight server boilerplate including the necessary Apache Spark suite of tools.
Why use EMR Serverless?
At Flexion, we used it for a client who requested a proof of concept from one of our teams. These teams use Spark jobs (with Deequ libraries) in EMR Clusters.
What is PyDeequ?
Another client also requested us to prove that PyDeequ can be used within EMR Serverless.
PyDeequ is a Python API for Deequ, a library built on top of Apache Spark for defining “unit tests for data,” which measure data quality in large datasets. PyDeequ is written to support the usage of Deequ in Python.
This blueprint demonstrates that PyDeequ can be used within EMR Serverless.
Benefits of EMR Serverless over Cluster
EMR Serverless provides a serverless runtime environment that simplifies the operation of analytics applications using the latest open-source frameworks, such as Apache Spark and Apache Hive. According to AWS, with EMR Serverless, we don’t have to configure, optimize, secure, or operate clusters to run applications using these frameworks.
- No cluster management: Unlike EMR Cluster, EMR Serverless does not need to handle the cluster lifecycle management and workload auto-scaling.
EMR Cluster out of the box requires knowledge of server cluster management for spinning up and tearing down clusters with all the accompanying overhead. - Quicker Start: Application/jobs start within a few minutes with EMR Serverless compared to the time it takes EMR Cluster to load the infrastructure.
Based on what we are running currently, EMR Serveless takes one-fourth of the time to start the application compared to the time it takes to start the EMR Cluster. - Scalability: No need to guess cluster sizes. EMR Serverless eliminates the need to right-size clusters for varying jobs and data sizes.
With EMR Serverless, we create an application using an open-source framework version and submit jobs to the application. EMR Serverless automatically adds and removes workers at different stages of processing the job. - Cost: EMR Serverless uses resources as needed, making it more cost-efficient than EMR Cluster, where resources are predefined.
With EMR Cluster, there is too much idle time when resources are not utilized or are underutilized. When using EMR Serverless, we experienced a cost reduction of up to 35 percent, with some test jobs set up for more than 75 million records. - Resilience to Availability Zone failures
It is a Regional service. When we submit jobs to an EMR Serverless application, it can run in any Availability Zone in the Region. - Integration with other AWS services
Logging, security, and networking can be seamless with easy integration of other AWS services.
Key considerations when using EMR Serverless vs. Cluster:
- Unlike EMR Cluster, there isn’t a native Step Action/s to interact with EMR Serverless directly. This must be done using a Lambda job to invoke an existing EMR Serverless Application.
- EMR Serverless has no out-of-the-box bootstrap process to install security software and other features, such as TenableNessus or Trend Micro, which are required in our AWS environment. However, this is possible by creating a custom EMR Serverless image.
- ECR image Scan: AWS provides two scanning options for ECR images: Enhanced scanning and Basic scanning. Enhanced scanning integrates with Amazon Inspector, scanning container images for both operating systems and code package vulnerabilities. This is an automated process from Amazon. Basic scanning integrates with the Common Vulnerabilities and Exposures (CVEs) database from the open-source Clair project, scans images on push, and performs manual scans.
EMR Serverless Job Setup
There are three essential components in EMR Serverless:
EMR Studio:
To create or manage EMR Serverless applications, we need the EMR Studio UI. An IAM service role is required to create a Studio, which defines the allowable actions for EMR Studio when provisioning resources. Examples of such actions include:
- Attaching a workspace to a cluster
- Accessing the S3 backup location for the workspace
- Interacting with other AWS services.
Application:
With EMR Serverless, we can create one or more EMR Serverless applications that use open-source analytics frameworks. To create an application, you must specify the following attributes:
- The Amazon EMR release version for the open-source framework version
- The specific runtime you want your application to use, such as Apache Spark or Apache Hive.
View the AWS diagram that illustrates the EMR Serverless application states trajectory.
Application Configurations without Network (VPC) connections*
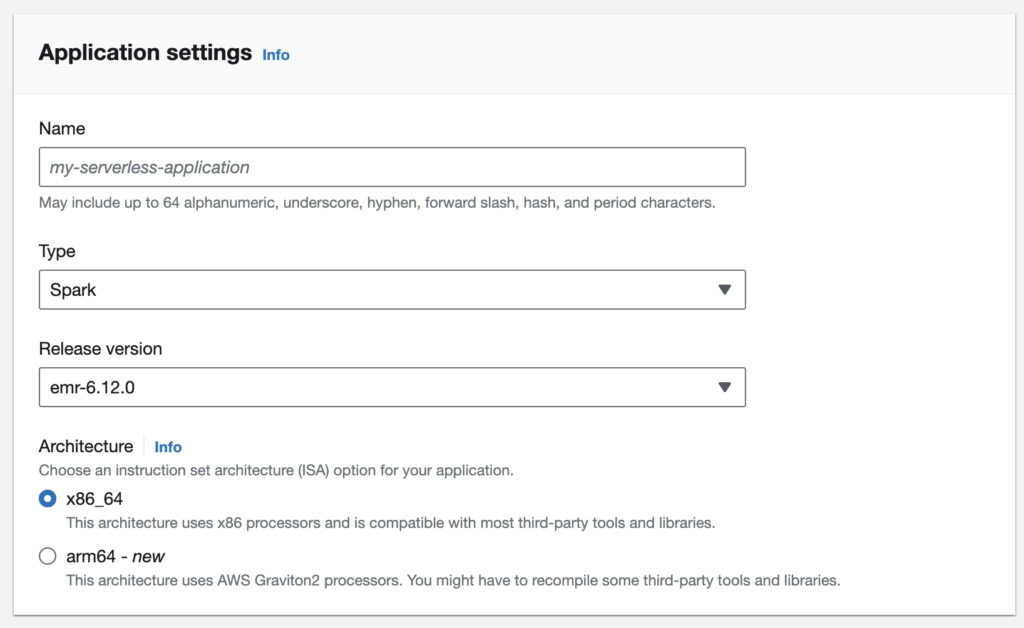
Application Configurations without Network (VPC) connections*
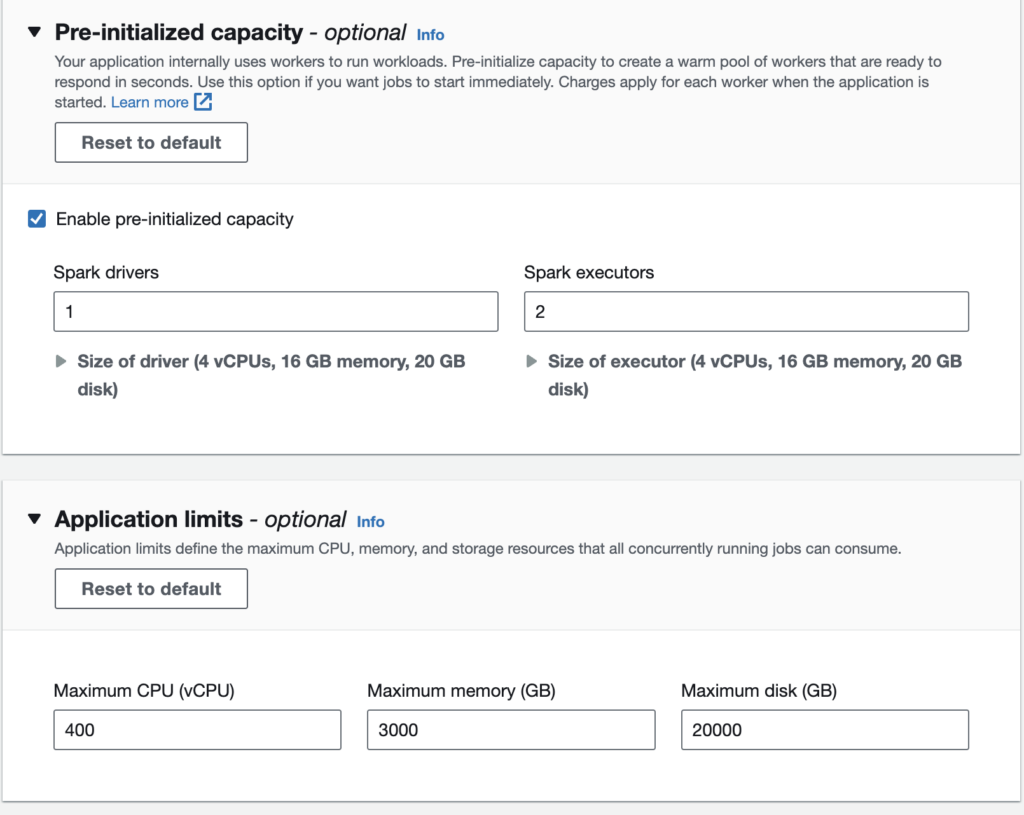
Application Configurations without Network (VPC) connections*
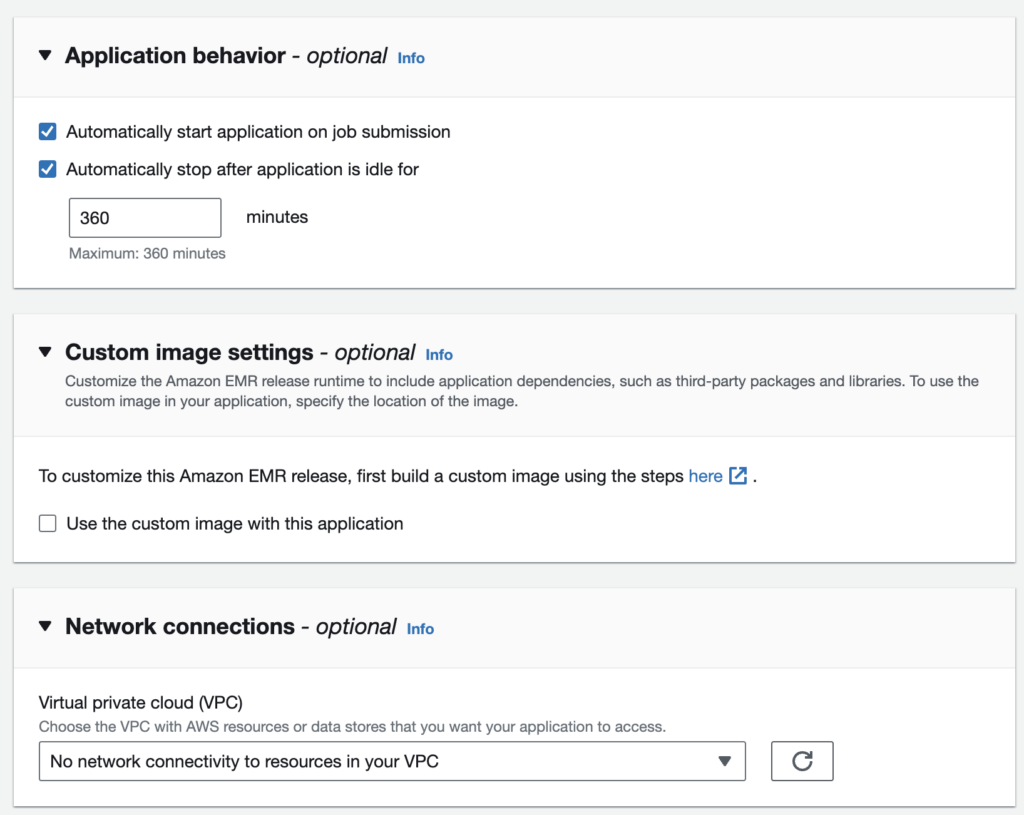
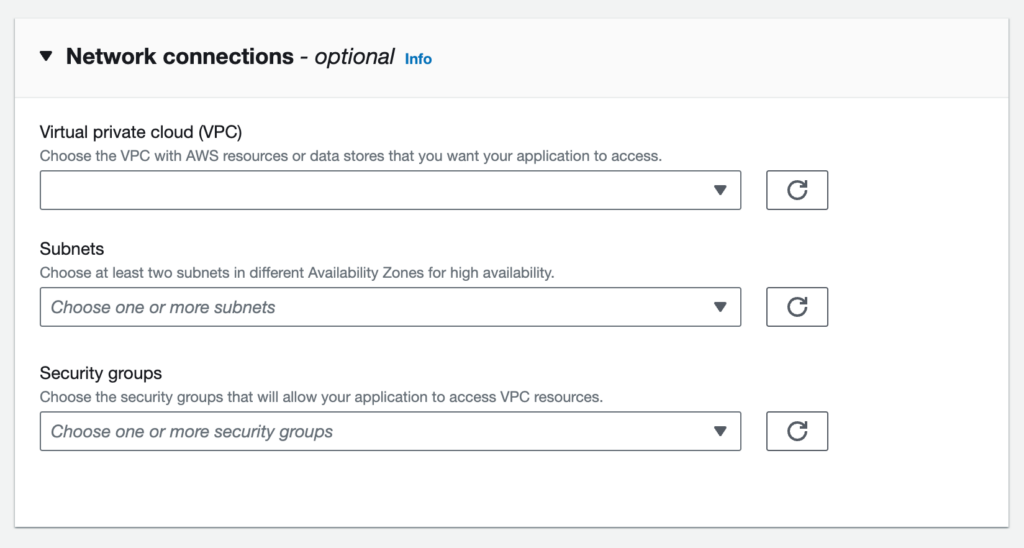
Application Configurations with Network (VPC) connections*
Application Configurations with Custom image settings*
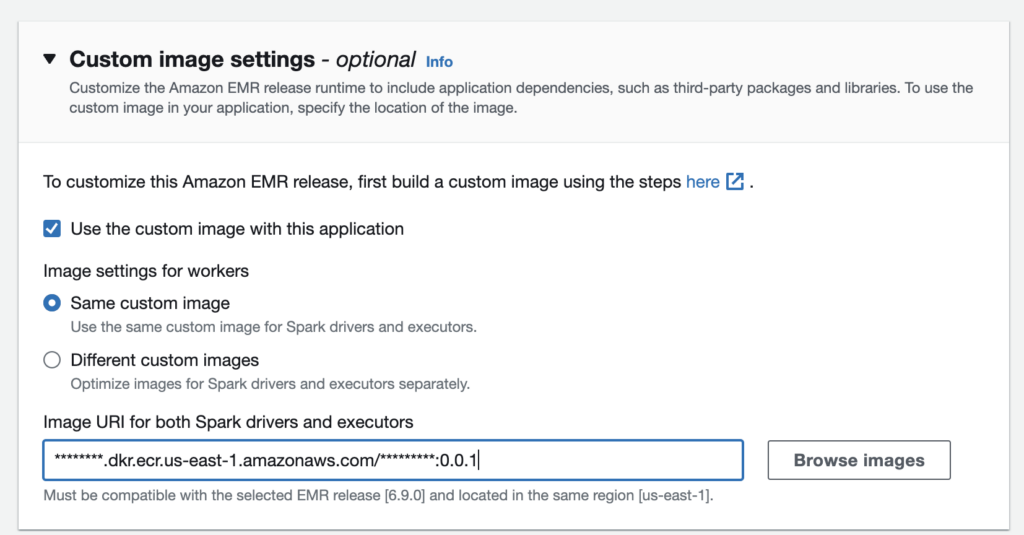
Follow these steps from Amazon to create and use a custom image.
Once the image is created, validate that it is correct by following these steps:
- Download the Python wheel:
<https://github.com/awslabs/amazon-emr-serverless-image-cli/releases/download/v0.0.1/amazon_emr_serverless_image_cli-0.0.1-py3-none-any.whl> - Install it with pip3:
pip3 install.
Job run
A job run is a request submitted to an EMR Serverless application that the application asynchronously executes and tracks through completion. A PySpark data processing script with Python is used to submit to an Apache Spark application for this proof of concept. This job uses the Deequ library for data quality, analysis, constraint checks, and validations.
Job configurations
- Job name:
<job name to be used>. - Script location: The location of the main JAR or Python script in Amazon S3 that we want to run.
- Runtime (Execution) role: IAM role for the job execution.
- Spark properties: Define the spark properties for the job.
- S3 URI for storing logs: The location in Amazon S3 where logs are stored.
Logging and monitoring
- To monitor job progress on EMR Serverless and to troubleshoot failures, we can choose how EMR Serverless stores and serves application logs. When submitting a job run, we can specify managed storage, Amazon S3, or both as logging options.
- To encrypt logs, specify the KMS (Key Management System) keys in the managedPersistenceMonitoringConfiguration configuration when using managed storage, and the s3MonitoringConfiguration configuration when using S3 storage.
- We can monitor capacity usage at the EMR Serverless application level using Amazon CloudWatch metrics.
Conclusion
While EMR Serveless can be an effective solution, some considerations are based on the jobs being set up. EMR Serverless is cost- and time-efficient. We use AWS ECR image scanning to ensure security compliance.
Gaurav Shekhadiya has worked on various cloud-based technologies, including AWS services and DevOps tools and practices over the past eight years. He has also helped clients adopt monitoring technologies. Gaurav has worked on Flexion’s Foundational Components team for the past year and a half and partners with other program development teams to help solve architectural problems and advocate for cross-product technical continuity.
* All screenshots are copyrighted by Amazon Web Services.


