

Document extraction to accelerate application processing
Transforming document submissions into accurate, machine-readable data to reduce administrative burden & speed up application processing

Challenge
Organizations across public & private sectors face three intertwined challenges that make document submission both a user pain point & an administrative quagmire:
- Rising mobile submissions, growing back-end burden
Nearly one-third of Americans earning under $30K rely solely on mobile phones for internet access, & since 2019, mobile-responsiveness in application portals has jumped 25%. Yet while front-end uploaders accept PDFs, photos, even crumpled or handwritten forms, these unstructured files shift work downstream. Administrators spend inordinate hours classifying, verifying, & keying in data from documents like W-2s, 1099s, DD214s, etc., delaying determinations & diverting staff from higher-value tasks. - Manual work & error risk
Because forms arrive in inconsistent formats, staff must decipher legibility issues, parse multi-part names, handle non-English characters, & wrestle with poor image quality. This manual extraction is slow, error-prone, & taxing—raising costs & delays for processors & applicants. - Procurement & technology gaps
Commercial OCR solutions can be expensive, hard to integrate, & often tied to multi-year projects that age before launch. Off-the-shelf tools demand heavy customization & external expertise—locking agencies into costly contracts & slowing iteration.
Potential cost savings for automating data extraction:
- Processing could be 3× faster per public/private case studies (e.g., USDA RPA case study).
- 50M hours of staff time could be saved across human services.
- Potential to reduce manual error rate from ~31% in manual document flows (ABBYY).
To break this cycle, organizations need a secure, scalable document-processing solution that can:
- Automatically classify commonly requested documents
- Accurately extract key fields—even from low-quality images
- Continuously improve via model training & feedback loops
- Work alongside existing case-management workflows & systems
- Deploy safely within a compliant, secure cloud environment
Teams must balance speed, ongoing costs, & maintainability—carefully weighing commercial vs. open-source OCR—so upgrades stay current, affordable, & under agency control.
Approach
We used a multi-phase, research-driven methodology. During Problem Framing & Validation (3 months), we created rapid low-fi mockups of submission & processing workflows, collected feedback from agency staff & document-solution experts, & ran a landscape scan to map vendor offerings & gaps—especially the lack of modular OCR/extraction services. Findings supported a hypothesis that automated document data extraction could deliver quick, high-impact wins.
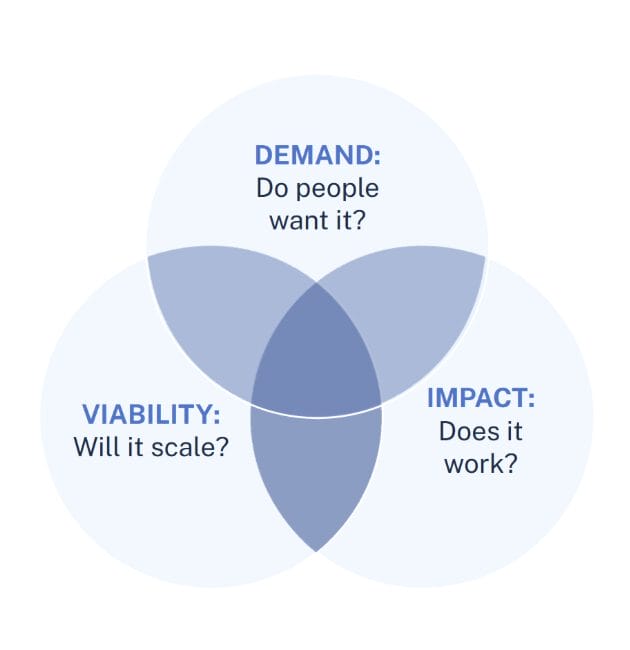
Using a “Desirable-Viable-Feasible” framework, we confirmed strong demand among state agencies & experts, compelling ROI via staff hours saved, technical feasibility with mature OCR (AWS Textract), & broad applicability.
We then rapidly prototyped a document-extractor PoC to test, refine, & scale.
Prototyping Phase
How might we convert uploaded documents (PDFs/images) into machine-readable data to reduce manual data-entry burden?
We built a web-based PoC that ingests PDFs/JPEGs/PNGs, extracts key fields via OCR+NLP, & presents editable fields alongside the source image for quick human review. Users export cleaned data as CSV or JSON for easy integration.
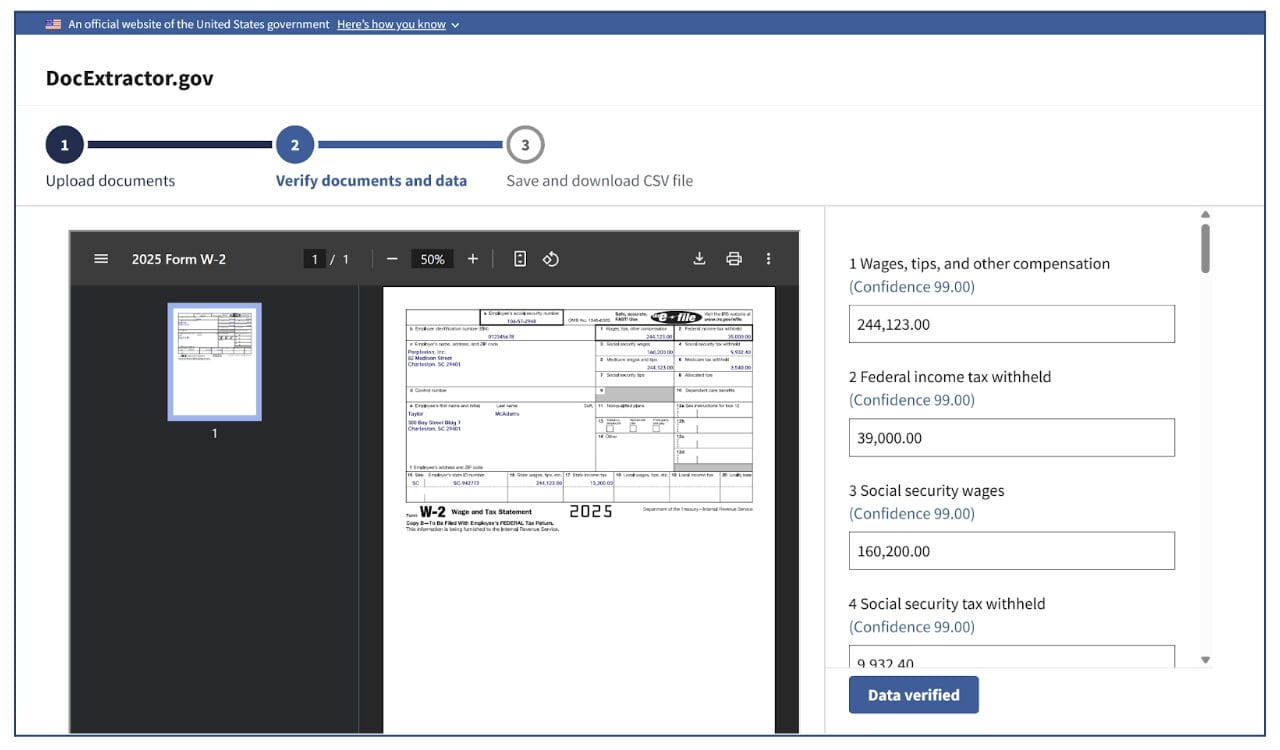
Baseline accuracy testing used real-world samples (W-2s, 1099s, DD214s) across formats (clean/crumpled photos, PDFs, screenshots). Comparing Tesseract, PaddleOCR, & EasyOCR showed AWS Textract was most accurate/adaptable for structured data—our chosen engine.
We added keyword+position logic to auto-classify form types (100% accurate in tests) & optimized back-end with Lambda pre-warming & SQS tuning—improving speed by 33%. Codebase modularization enabled robust unit tests; authentication hardened security.
Training with diverse datasets (edge-case names & non-English characters) yielded a 14% accuracy lift. Textract queries reduced noise & improved field-level accuracy. We refactored for modularity, set up CI/CD with GitHub Actions, & deployed to AWS.
UI enhancements (clear classification labels, responsive loaders) improved perceived speed & trust—keeping UX seamless as capability grew.
Outcomes
Across three testing rounds with real & synthetic docs, average accuracy improved 14%. We achieved 100% extraction accuracy for 1099s & 99% for W-2s. Platform optimizations cut processing time by 33%. The app was securely deployed with automated releases, meeting operational compliance, while UI feedback improved reviewer confidence.
Future potential
The PoC opens several promising paths:
- Agency-facing deployment & low-code integration:
- Production deployments for agencies & private orgs to improve internal processing.
- Low-code mapping interface so staff can connect extracted fields to existing workflows without heavy engineering.
- Expanded document coverage with more training data (multi-page, handwritten).
- User feedback loops to flag anomalies & continuously train models.
- ATO readiness groundwork in place for a production-grade path when needed.
Looking to build a human-centered solution with secure, scalable deployment? Flexion can help.
Ready to change the way you’re doing business?
Contact us to talk about how Flexion can help your organization drive efficiency, optimize costs, and achieve your technology goals!
