

Bringing Nepal’s student voices into the digital age
Flexion and Canopy Nepal’s path from paper to digital learning

Challenge
Canopy Nepal’s Katha Bunaun – Weaving Stories program helps students build voice, confidence, and critical thinking through creative writing. Each student completes pre- and post-evaluation stories in English and Nepali, captured in paper workbooks and scored using a detailed rubric that looks beyond mechanics to creativity, self-expression, and social-emotional growth.
Canopy Nepal faces three converging challenges as their storytelling program scales:
- Impact data is locked in paper
Tens of thousands of handwritten English and Nepali stories live only in printed workbooks, preventing timely analysis, delaying feedback to students, and slowing reporting to stakeholders. - Manual scoring doesn’t scale
Each story requires nuanced, rubric-based scoring that evaluates creativity, detail, organization, and voice. As the program grows, the time burden limits staff capacity for facilitation and expansion. - Donors expect a digital and AI-enabled future
Canopy’s roadmap includes hybrid and digital delivery. To unlock funding, they needed a credible demonstration of how AI could support, but not replace human-centered literacy development.
Approach
Over a focused three-week proof of concept (POC), Flexion and Canopy pursued two parallel workstreams. First, we built an AI-assisted scoring pipeline for handwritten English and Nepali stories, including OCR benchmarking, data preparation, and rubric-aligned scoring experiments. In parallel, we designed a mobile-first prototype to explore how students could complete storytelling activities digitally and receive meaningful feedback in a format aligned with their real-world contexts.
Workstream 1 – Establishing an AI-assisted scoring pipeline
a. Data preparation and alignment with Canopy’s rubric
Flexion worked closely with Canopy to select an initial set of handwritten student stories that were representative of the broader archive. Using a custom-built script, the team pulled PDFs of student work from a shared Google Drive folder and cross-referenced each story with existing human scores stored in the Stories Data Roster and accompanying assessment sheets. To support reliable comparison and model tuning, a subset of OCR outputs was manually reviewed and validated, creating a small “gold” dataset that served as a benchmark for evaluating OCR tools and refining the scoring pipeline.
Preparing the data surfaced a number of practical challenges typical of large-scale, paper-based programs. These included ink bleeding and low-contrast scans, PDFs that bundled multiple students’ work together, multi-tab scoring sheets with inconsistent structures, student name mismatches, variations between scoring dataset versions, and the need to handle both English and Nepali scripts within a single pipeline.
b. Evaluating OCR options
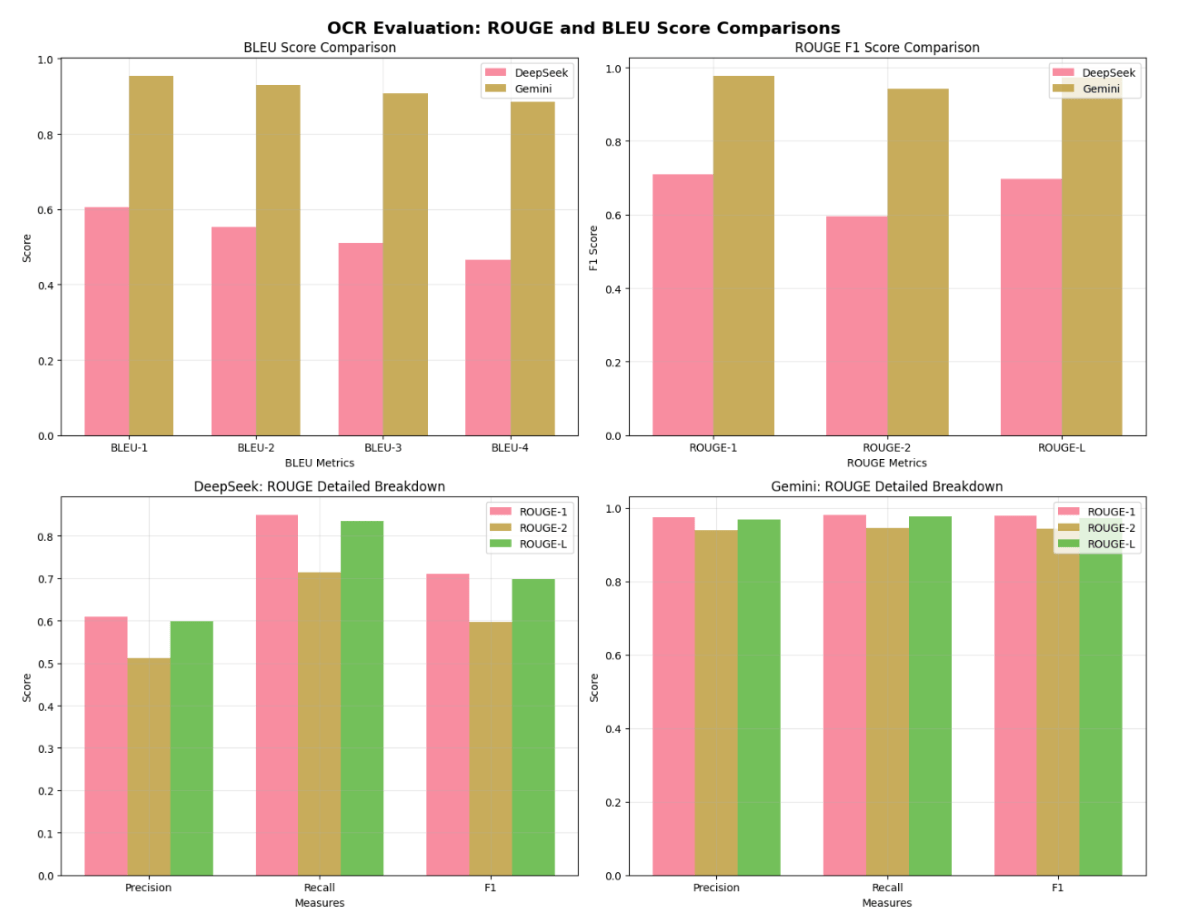
Because the stories were handwritten, bilingual, and often captured via scans or photos, OCR reliability was a central risk. The team evaluated several tools, including DeepSeek OCR, AWS Textract, and Chandra OCR. Textract was eliminated due to limited Nepali language support, while Chandra proved too slow for large-scale use. Through BLEU and ROUGE benchmarking against a manually validated “gold” dataset, Google Gemini consistently demonstrated stronger text accuracy, better preservation of narrative structure, and more reliable handling of multi-page documents. As a result, Gemini was selected as the preferred OCR engine for the POC.
c. Turning OCR into structured, analyzable data
Once Gemini was selected, the team built a pipeline to run all selected PDFs through Gemini. We then normalized and cleaned extracted text (while preserving story content and paragraph breaks). The team joined the text with human scoring data in a single dataframe, ready for model training and analysis. And then we logged edge cases (e.g., mislabeled PDFs such as non-story content) to refine file handling and improve upstream data hygiene.
d. Prototyping rubric-aligned AI scoring
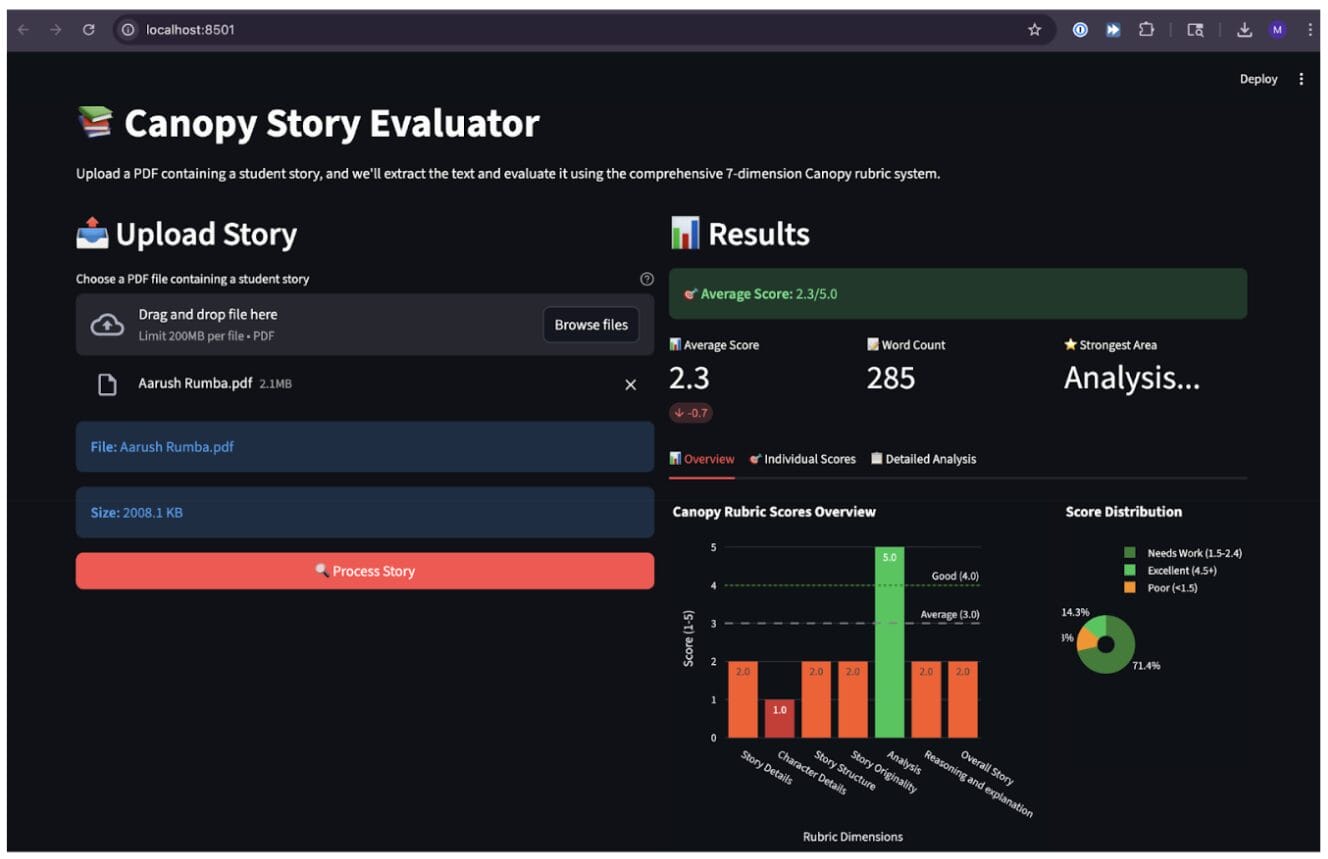
Using the combined dataset of story text, human scores, and rubric criteria, we began experimenting with rubric-driven AI scoring by encoding Canopy’s dimensions, such as creativity, detail, organization, self-expression, and critical thinking, into structured prompts and scoring instructions. The model generated predicted scores for each story, which we then compared directly to the human-assigned rubric scores.
Comparing AI-generated scores with human rubric scores revealed clear patterns. Alignment was strongest for stories that were clearly high- or low-quality, where rubric criteria were more explicit. Alignment decreased in more nuanced cases involving creativity and voice, reinforcing the importance of human oversight. These findings helped define where AI could reliably support scoring at scale, and where educator judgment remains essential.
Workstream 2 – Prototyping a mobile-first student experience
Because mobile phones are more accessible to students in Nepal than laptops or Chromebooks, the design team centered the prototype around a mobile-first experience. To begin, we mapped the entire Katha Bunaun workbook inside FigJam to fully understand the structure of the program, the narrative arc students move through, and how the pre- and post-evaluations fit into the broader learning journey. This gave us clarity on where AI-powered scoring and feedback could appear without interrupting the storytelling process. It also helped us map specific rubric elements, such as creativity, detail, or organization, to key points in the student journey, informing which components the interface needed to capture and when.
With that understanding, the team designed a kid-friendly, phone-optimized interface in Figma. The prototype featured a simple, inviting prompt screen, followed by a clean, full-screen writing experience that minimized distractions and encouraged students to focus on their story. Clear calls to action guided students through the activity without overwhelming them. Throughout the design, we incorporated accessibility and cognitive-load considerations by reducing dense text, strengthening the visual hierarchy, increasing spacing for readability, and relying on patterns that support multilingual and low-bandwidth environments common across Nepal.
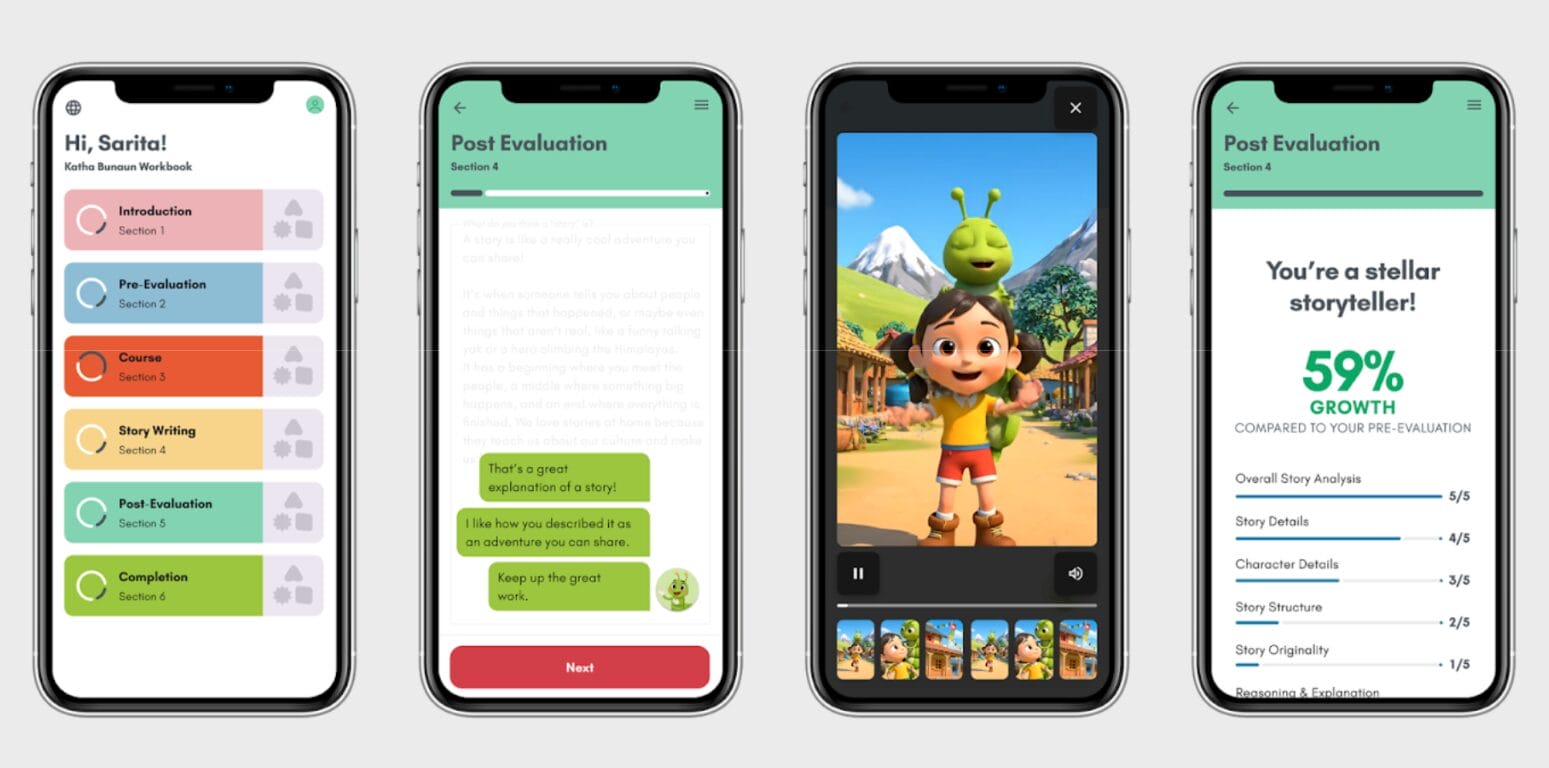
To help students understand progress and growth, the team explored several approaches to visualizing AI-assisted scores, including comparative pre- and post-evaluation views and layouts optimized to minimize scrolling on mobile devices. Through iteration and review with Canopy leadership, a horizontal bar chart design was selected, pairing numeric scores with a familiar visual scale that closely mirrors the paper-based experience while remaining easy to read on a phone.
To further reduce cognitive load, especially given the workbook’s heavy, text-dense format, we also experimented with transforming select pages into short, portrait-format instructional videos. These videos enabled us to break down dense content through controlled pacing and supportive visuals, increase student engagement with motion, narration, and storytelling, and better support diverse learners, including ELL students, struggling readers, and students with ADHD. Instructional videos would also allow us to model processes and step-by-step tasks more clearly than static print, while aligning with digital-native expectations to deliver a more intuitive and effective user experience.
Using Google Cloud Platform Veo 3.1, OpenAI Sora, and Google Gemini, we created concept videos that rephrased instructions into student-friendly language and combined narration with simple visuals. These videos were designed to integrate directly into the digital workbook, introducing activities, demonstrating what strong stories look like, and supporting students who may struggle with long blocks of text or complex directions.
Key learnings from AI video experiments
Early experiments with AI-generated instructional video revealed strong potential for translating dense workbook content into more accessible, multimodal formats, but also surfaced important limitations. Free-tier tools were constrained by credit limits, allowing only brief clips and limiting rapid iteration. Across tools, visual continuity proved difficult to maintain: characters, props, and scenes often shifted between clips even when prompts remained unchanged. Audio output was similarly inconsistent, with confusion between voiceover narration and character dialogue, uneven lip-syncing, and variable pacing.
These findings reinforced that AI-generated video is best positioned as a rapid prototyping or first-draft tool rather than a production-ready solution. More consistent results require paid access, stronger use of reference images and prompt constraints, and post-production editing, such as human voiceover and manual audio synchronization, to achieve the emotional depth and polish needed for classroom use.
Outcomes
Even within a short POC window, the collaboration generated tangible artifacts and clear next steps for both Canopy and Flexion.
For Canopy Nepal, the POC produced an AI-ready dataset combining student stories, human scores, and rubric dimensions, positioning the organization to analyze growth patterns across cohorts and scale toward its full archive of 40,000 stories. The work also validated a practical OCR and scoring approach for handwritten English and Nepali content, establishing a foundation that can be iteratively calibrated over time.
In parallel, the team delivered a clickable, mobile-first prototype demonstrating how students could complete storytelling activities digitally, receive feedback, and see their growth over time. Canopy leadership reviewed and approved multiple score-visualization options, selecting a design that balances clarity with familiarity.
Together, these artifacts form a compelling narrative for funders and partners that show how student creativity can be honored, measured, and scaled without losing the heart of the program.
Future potential
Although this proof of concept was intentionally scoped as a lightweight, low-risk exploration, it points to several meaningful opportunities for continued growth. The OCR and scoring pipeline could be extended across Canopy’s full archive of handwritten stories—up to 40,000 entries—enabling longitudinal analysis of student growth and providing a richer, data-backed view of program impact over time.
Building on this foundation, Canopy could introduce teacher and facilitator dashboards that surface class-level trends, support reporting needs, and help identify students who may benefit from additional support. The mobile-first prototype could also evolve into a full digital or hybrid workbook experience, allowing students to complete stories on mobile phones or shared devices, receive immediate feedback, engage with age-appropriate gamified elements such as badges, and access supporting digital content, including instructional videos.
Beyond Canopy Nepal, the same approach could be replicated through broader partnerships, applying the model to other regions and languages where educational programs continue to rely heavily on paper-based materials.
Ready to change the way you’re doing business?
Contact us to talk about how Flexion can help your organization drive efficiency, optimize costs, and achieve your technology goals!
